This project is available on GitHub.
Boolean Algebra
A Boolean algebra is a mathematical structure that captures the properties of logical operations and sets. Formally, it is a 6-tuple $(B, \land, \lor, \neg, 0, 1)$, where
- $B$ is a set of elements,
- $\land$ ($\rm{and}$) and $\lor$ ($\rm{or}$) are binary operations on $B$,
- $\neg$ ($\rm{not}$) is a unary operation on $B$,
- $0$ and $1$ are elements of $B$, the minimum and maximum elements.
These must satisfy the usual axioms: closure, commutativity, associativity, distributivity, identity, and complements [1].
Boolean algebras show up everywhere. They form the foundation of propositional logic and are fundamental to digital circuit design and computer architecture [2].
In set theory, the standard representation is the power set of a set $X$, denoted $\mathcal{P}(X)$:
- $B = \mathcal{P}(X)$,
- $\land = \cap$ (set intersection),
- $\lor = \cup$ (set union),
- $\neg = \complement$ (set complement),
- $0 = \emptyset$ (empty set),
- $1 = X$ (universal set).
This set-theoretic Boolean algebra, $(\mathcal{P}(X), \cap, \cup, \complement, \emptyset, X)$, is the canonical example and the starting point for what follows: a Boolean algebra over trapdoors [3]. The construction preserves the familiar Boolean algebra properties while introducing cryptographic elements for secure computations.
Homomorphisms in Boolean Algebra
A homomorphism is a structure-preserving map between two algebraic structures of the same type. For Boolean algebras, it is a function that preserves the operations and special elements.
Given two Boolean algebras $(A, \land_A, \lor_A, \neg_A, 0_A, 1_A)$ and $(B, \land_B, \lor_B, \neg_B, 0_B, 1_B)$, a function $f: A \to B$ is a Boolean algebra homomorphism if for all $x, y \in A$:
- $f(x \land_A y) = f(x) \land_B f(y)$
- $f(x \lor_A y) = f(x) \lor_B f(y)$
- $f(\neg_A x) = \neg_B f(x)$
- $f(0_A) = 0_B$
- $f(1_A) = 1_B$
A homomorphism preserves structure across the mapping: you can perform operations in one algebra and have them correspond to operations in the other [4].
This matters because it lets us build a mapping between our original Boolean algebra and a new structure with cryptographic elements while still maintaining the essential properties. Operations in the trapdoor algebra remain logically consistent with standard Boolean operations.
In the following sections, I introduce a specific homomorphism $F$ that maps elements from our original algebra to a Boolean algebra over bit strings, incorporating a cryptographic hash function. This homomorphism is the foundation of the Boolean algebra over trapdoors.
The Bernoulli Model
Before introducing the Bernoulli homomorphism, I need to cover the underlying framework: the Bernoulli model.
The Bernoulli model is a probabilistic framework for representing and reasoning about approximations of values. A value can be anything from a set, whether that set is something simple like $\lbrace\rm{true}, \rm{false}\rbrace$ or the set of functions $X \to Y$ (I call these Bernoulli maps in the general case).
It introduces controlled uncertainty into computations, allowing trade-offs between accuracy and other desirable properties like space efficiency or security.
Formally, for any type $\mathcal{T}$, we define its Bernoulli approximation as
$$ B_{\mathcal{T}}. $$When we observe a value from the Bernoulli Model process, we write $B_{\mathcal{T}}(x)$, where $x$ is the latent value of type $\mathcal{T}$ that we cannot observe directly. The model introduces an error probability $\epsilon(x)$:
$$ \Pr\bigl\lbrace B_{\mathcal{T}}(x) \neq x \bigr\rbrace = \epsilon(x). $$For a first-order Bernoulli model, $\epsilon(x) = \epsilon$ for all $x \in \mathcal{T}$, i.e., a constant (and usually known) probability. We say the order is $k=1$. For instance, a noisy binary symmetric channel might have $\epsilon = 0.1$, meaning every observed value has a 10% chance of being wrong. For higher-order models, $\epsilon : \mathcal{T} \mapsto [0,1]$ represents error probabilities under different conditions.
Key properties:
Propagation of uncertainty: When operations are performed on Bernoulli approximations, uncertainties combine in well-defined ways.
Trade-off between accuracy and other properties: By adjusting the probabilities, we balance accuracy against other characteristics.
Generalization to complex types: The model applies to simple types like Booleans and to complex types including functions and algebraic structures.
In this work, the Bernoulli Model provides the framework for analyzing the behavior of our cryptographic constructions.
A Boolean Algebra Over Free Semigroups
Consider the Boolean algebra
$$ A := (\mathcal{P}\bigl(X^{\ast}), \land = \cap, \lor = \cup, \neg = \complement, 0 = \emptyset, 1 = X^{\ast}\bigr) $$where $\mathcal{P}$ is the powerset, $X$ is an alphabet, and $X^{\ast}$ is the free semigroup on $X$, closed under concatenation:
$$ \# : X^{\ast} \times X^{\ast} \mapsto X^{\ast}. $$For example, if
$$ X = \lbrace a,b\rbrace $$then
$$ X^{\ast} = \lbrace\epsilon, a, b, aa, ab, ba, bb, aaa, aab, \ldots \rbrace $$and
$$ \mathcal{P}(X^{\ast}) = \bigl\lbrace\emptyset, \lbrace\epsilon\rbrace, \lbrace a\rbrace, \lbrace b\rbrace, \lbrace aa\rbrace, \ldots, \lbrace\epsilon,a\rbrace, \ldots, \lbrace a,a,babb\rbrace, \ldots \bigr\rbrace, $$where $\epsilon$ is the empty string.
For Boolean algebras over finite sets, a standard approach is to represent sets as bit strings of length $n$: the mapping $\mathbb{A} \mapsto a_1 \ldots a_n$ where bit $a_j = 1$ if the $j$-th element (under some ordering) is in $\mathbb{A}$, otherwise $a_j = 0$. With $n$ bits, you can uniquely represent $2^n$ sets.
Our case is harder because we have a Boolean algebra over the infinitely large free semigroup $X^{\ast}$. The plan is to stick with the finite bit string representation, accepting a controllable error on membership queries: the false positive rate (probability that an element not in the set falsely tests positive), assuming elements are selected randomly from $X^{\ast}$.
We map elements of $X^{\ast}$ to bit strings in $\lbrace0,1\rbrace^2$ using a cryptographic hash function $h : X^{\ast} \mapsto \lbrace0,1\rbrace^2$. If we randomly choose two elements of $X^{\ast}$, the collision probability is $2^{-n}$. Collisions are the fundamental source of error, and this is what makes the approximate Boolean algebra a Bernoulli Model process.
Approximate Boolean Algebra Over Trapdoors
Consider the Boolean algebra
$$ B := \bigl(\lbrace0,1\rbrace^n, \&, |, \sim, 0^n, 1^n\bigr) $$where $&$, $|$, and $\sim$ are the bitwise $\operatorname{and}$, $\operatorname{or}$, and $\operatorname{not}$. We define a homomorphism $F$:
$$ \begin{align*} F (\cap) &= |,\\ F (\cup) &= \&\\ F (\complement) &= \sim,\\ F (\emptyset) &= 0^n,\\ F (X^{\ast}) &= 1^n,\\ F (\lbrace x_{j_1}, \ldots, x_{j_k}\rbrace) &= 0^n | h(x_{j_1}) | \cdots | h(x_{j_k}), \end{align*} $$where $h : X^{\ast} \mapsto \lbrace0,1\rbrace^n$ is a cryptographic hash function, $s \in X^{\ast}$ is a secret, and $\lbrace x_{j_1}, \ldots, x_{j_k}\rbrace \subseteq X^{\ast}$.
Operations in $A$ are set operations; operations in $B$ are bitwise operations. For example, suppose $x,y \in \mathcal{P}(X^{\ast})$ with $y \subset x$. If $F(x) = 0110$ and $F(y) = 0010$, then $F(x \land_A y) = F(x) \land_B F(y) = 0110 | 0010 = 00010 = F(y)$.
We assume $h$ distributes uniformly over $\lbrace0,1\rbrace^n$, so the a priori collision probability between two elements is $2^{-n}$.
If we map $A$ to $B$ via homomorphism $F$ and apply the same operations in both, we get a representation of the result in $B$ for the ground truth in $A$. But if we query $A$ and $B$ for membership, we may see discrepancies. The homomorphism $F$ itself is approximate in the negation operation: $F(\neg_A x) \neq \neg_B F(x)$.
These discrepancies come from the finite number ($2^n$) of bit strings used to represent elements of $\mathcal{P}(X^{\ast})$. So $B$ is an approximate Boolean algebra when used to model operations in $A$. The approximation error is controllable by changing $n$, and different operations have different error rates.
The cryptographic hash function $h$ is one-way: computationally infeasible (actually impossible, since the mapping is non-injective) to reverse. This is crucial for security, ensuring original elements in $X^{\ast}$ cannot be reconstructed from their bit string representations. Since $F$ uses $h$, it is an approximate one-way homomorphism mapping Boolean algebra $A$ to Boolean algebra $B$ over trapdoors.
Homomorphism Properties
We have Boolean algebras $A$ and $B$ as described. We want to model operations in $A$ using $B$ via $F$. In the proofs below, let $X = \lbrace a,b\rbrace$ with $x = \lbrace a,b,ab\rbrace$ and $y = \lbrace b,ab,bb\rbrace$.
The homomorphism must satisfy:
- $F(x \land_A y) = F(x) \land_B F(y)$
- $F(x \lor_A y) = F(x) \lor_B F(y)$
- $F(\neg_A x) = \neg_B F(x)$
- $F(0_A) = 0_B$
- $F(1_A) = 1_B$
I show these hold for all properties except the third, which fails due to the approximate nature of the algebra. So $F$ is an approximate Boolean algebra homomorphism.
Proof of First Property: We want $F(x \land_A y) = F(x) \land_B F(y)$. From the LHS:
$$ \begin{align*} F(x \land_A y) &= F(x \cap y) \\ &= F(\lbrace b,ab\rbrace) \\ &= 0^n | h(b) | h(ab). \end{align*} $$From the RHS:
$$ F(x) \land_B F(y) = \bigl(h(a) | h(b) | h(ab)\bigr) \& \bigl(h(b) | h(ab) | h(bb)\bigr). $$Since $&$ and $|$ are bitwise $\operatorname{and}$ and $\operatorname{or}$, only the bits corresponding to hashes appearing in both groups survive the $\operatorname{and}$. Only $h(b)$ and $h(ab)$ appear in both, so:
$$ F(x) \land_A F(y) = h(b) | h(ab). $$Thus $F(x \land_A y) = F(x) \land_B F(y)$, and this generalizes to any two sets in $A$.
Proof of Second Property: We want $F(x \lor_A y) = F(x) \lor_B F(y)$. From the LHS:
$$ \begin{align*} F(x \lor_A y) &= F(x \cup y) \\ &= F(\lbrace a,b,ab,bb\rbrace) \\ &= 0^n | h(a) | h(b) | h(ab) | h(bb). \end{align*} $$From the RHS:
$$ F(x) \lor_B F(y) = \bigl(0^n | h(a) | h(b) | h(ab)\bigr) | \bigl(0^n | h(b) | h(ab) | h(bb)\bigr). $$By commutativity, associativity, and idempotency of bitwise $\operatorname{or}$:
$$ F(x) \lor_B F(y) = 0^n | h(a) | h(b) | h(ab) | h(bb). $$So $F(x \lor_A y) = F(x) \lor_B F(y)$. This generalizes to any two sets in $A$.
Proof of Fourth Property: $F(0_A) = F(\emptyset) = 0^n = 0_B$. Trivial by definition.
Proof of Fifth Property: $F(1_A) = F(X^{\ast}) = 1^n = 1_B$. Also trivial by definition.
We proved properties 1, 2, 4, and 5. Note that we did not show identities like
$$ F(\lbrace a,b,ab\rbrace \land_A \lbrace b,ab,bb\rbrace) = F^{-1}(F(\lbrace a,b,ab\rbrace) \land_B F(\lbrace b,ab,bb\rbrace), $$since $F$ is one-way and has no inverse. Now I show that property 3 does not hold.
Disproof of Third Property: We want to disprove $F(\neg_A x) = \neg_B F(x)$. Starting from the LHS:
$$ \begin{align*} F(\neg_A x) &= F(x^\complement) \\ &= F(X^{\ast} \setminus \lbrace a,b,ab\rbrace), \end{align*} $$which is an infinite set containing everything in $X^{\ast}$ except $a$, $b$, and $ab$. It includes $bb$, $aaaaabbabababa$, $\epsilon$, and so on.
Assuming $h$ distributes these uniformly over bit strings of length $n$, by the pigeonhole principle, every bit string in $\lbrace0,1\rbrace^n$ has multiple elements hashing to it. Applying $F$ to the complement:
$$ F(\neg_A x) = 0^n | h(bb) | h(aaaabbbabababa) | \cdots, $$the result is all ones:
$$ F(\neg_A x) = 1^n. $$From the RHS:
$$ \neg_B F(x) = \sim \bigl(0^n | h(a) | h(b) | h(ab)\bigr). $$This is a finite number of elements OR-ed together, then bitwise NOT-ed. Due to the hash function, some bit positions will be 1 and others 0, giving a bit string that is not all ones:
$$ \neg_B F(x) \neq 1^n. $$So $F(\neg_A x) \neq \neg_B F(x)$. As $|x|$ increases, the probability that $F(\neg_A x) = 0^n$ approaches 1, and asymptotically as $|x| \to \infty$ the third property holds. But in general, $F$ is only an approximate Boolean algebra homomorphism.
Single-Level Hashing Scheme
In the next section I introduce a two-level hashing scheme that reduces space complexity. First, I derive the space complexity of the single-level scheme for representing free semigroups as “dense” bit strings of size $n$. The punchline: to keep false positive rates on membership ($\in_B$) and subset ($\subseteq_B$) constant, the number of bits $n$ must grow exponentially with the number of elements. This limits the scheme to very small sets. The two-level scheme addresses this.
I derive the single-level scheme first because it is theoretically interesting and provides the foundation for the two-level scheme.
Relational Predicates
Here I view the Boolean algebra in a set-theoretic context and define the fundamental predicates: membership and subset relations.
Set Membership
Set membership $\in$ tests whether an element is in a set. Boolean algebra $A$ has:
$$ \in_A : X^{\ast} \times 2^{X^{\ast}} \mapsto \mathrm{bool} $$defined as
$$ a \in_A b := 1_b(a), $$where $1_b$ is the set indicator function.
For approximate Boolean algebra $B$:
$$ \in_B : \lbrace0,1\rbrace^n \times \mathcal{P}(\lbrace0,1\rbrace^n) \mapsto \mathrm{bool} $$defined as
$$ a \in_B b := a \land_B b = a. $$This means we test membership by checking that if $h(a)$ has a bit set to 1, that bit must also be set in $h(b)$. This permits false positives: $a \in_B b$ may test true even if $a \notin_A b$.
When we take the union of two sets, we take the bitwise $\operatorname{or}$ of the two bit strings. Consider two edge cases. The empty set $0_A = \emptyset$ has representation $F 0_B = 0^n$, and the singleton $\lbrace a\rbrace$ has representation $F \lbrace a\rbrace = h(a)$. Their union:
$$ (F \emptyset) \lor_B (F \lbrace a\rbrace) = 0^n | h(a) = h(a). $$Similarly, the universal set $X$ with representation $F X = 1^n$ and singleton $\lbrace a\rbrace$:
$$ (F X) \lor_B (F \lbrace a\rbrace) = 0^n | h(a) = 1^n. $$Now consider the union of two singletons $\lbrace a\rbrace$ and $\lbrace b\rbrace$:
$$ (F \lbrace a\rbrace) \lor_B (F \lbrace b\rbrace) = h(a) | h(b). $$Let $Y = h(\lbrace a\rbrace)$ and $Z = h(\lbrace b\rbrace)$. The probability that the $j$-th bit is 1 in $Y$ is $1/2$, same for $Z$. The probability that the $j$-th bit is 1 in $X = Y \lor_B Z$:
$$ \begin{align*} \Pr\lbrace X_j = 1\rbrace &= \Pr\lbrace Y_j | Z_j = 1\rbrace\\ &= \Pr\lbrace(Y_j = 1) \lor (Z_j = 1)\rbrace. \end{align*} $$By De Morgan’s laws:
$$ \begin{align*} \Pr\lbrace Y_j = 1 \lor Z_j = 1\rbrace &= 1 - \Pr\Bigr\lbrace(Y_j = 0) \land (Z_j = 0)\Bigr\rbrace. \end{align*} $$By independence:
$$ \Pr\lbrace Y_j = 1 \lor Z_j = 1\rbrace = 1 - \Pr\lbrace Y_j = 0\rbrace \Pr\lbrace Z_j = 0\rbrace, $$and since $h$ is uniform over $\lbrace0,1\rbrace^n$, each bit is 0 with probability $1/2$:
$$ \Pr\lbrace Y_j = 1 \lor Z_j = 1\rbrace = 1 - 2^{-2}. $$Generalizing to $k$ unions of unique singletons:
$$ \Pr\lbrace X_j = 1\rbrace = 1 - 2^{-k}. $$Using the approximation $(1 - y) \approx e^{-y}$ for small $y$, with $y = 2^{-k}$:
$$ \Pr\lbrace X_j = 1\rbrace \approx e^{-1/2^k}. $$The probability that all bits are 1:
$$ \Pr\lbrace X = 1^n\rbrace = \prod_{j=1}^{n} \Pr\lbrace X_j = 1\rbrace = \bigl(1 - 2^{-k}\bigr)^n \approx e^{-n/2^k}. $$Since $e^{-n/2^k} \to 1$ as $k \to \infty$, the union of $k$ singletons converges in probability to the universal set $1^n$. At that point, further unions change nothing.
False Negatives and False Positives
Suppose we have a set $W$ and want to test if a randomly chosen $x \in X$ is a member. Let $h$ be the hash of $x$ with $j$-th bit $h_j$. If $x$ actually is in $W$, all bits set to 1 in $F x$ are also 1 in $F W$ by construction. The false negative rate is $0$.
If $x$ is not in $W$, a false positive may occur. For a false positive, every bit where $h_j = 1$ must also be 1 in $W_j$. This is logical implication:
$$ h_j = 1 \implies W_j = 1. $$Equivalently:
$$ \lnot ( h_j = 1 \land W_j = 0 ). $$The probability:
$$ \begin{align*} \Pr\lbrace\lnot ( h_j = 1 \land W_j = 0)\rbrace &= 1 - \Pr\lbrace h_j = 1 \rbrace \Pr\lbrace W_j = 0\rbrace. \end{align*} $$With $h$ uniform, $\Pr\lbrace h_j = 1\rbrace = 1/2$. After $k$ unions, $\Pr\lbrace W_j = 0\rbrace = 2^{-k}$. Therefore:
$$ \Pr\lbrace\lnot ( h_j = 1 \land W_j = 0)\rbrace = 1 - 2^{-(k+1)}. $$For a false positive, this must hold for all $n$ bit positions:
$$ \begin{align*} \varepsilon &= \Pr\lbrace\text{$x \in W$ is a false positive}\rbrace\\ &= \prod_{j=1}^{n} (1 - 2^{-(k+1)})\\ &= (1 - 2^{-(k+1)})^n. \end{align*} $$Asymptotic False Positive Rate
Using the approximation $(1 - y) \approx e^{-y}$ with $y = 2^{-(k+1)}$:
$$ \varepsilon_{\in} \approx e^{-n 2^{-(k+1)}}, $$which holds even for relatively small $k$. In Big-O notation, fixing $n$:
$$ \varepsilon_{\in} = e^{\mathcal{O}(2^{-k})}, $$meaning $\varepsilon$ approaches 1 exponentially fast as $k$ increases.
Space Complexity
Rewriting $n$ as a function of $\varepsilon$ and $k$:
$$ n = \frac{\log \varepsilon}{\log(1 - 2^{-(k+1)})}. $$For small $x$, $\log(1 - x) \approx -x$, so:
$$ n \approx \frac{\log \varepsilon}{2^{-(k+1)}}. $$Holding $\varepsilon$ constant:
$$ n = \mathcal{O}(2^k), $$meaning the number of bits must grow exponentially with the set size to maintain a fixed error rate. This limits the scheme to very small sets.
The false positive probability depends on both $k$ (set size) and $n$ (bits in the representation). Unsurprisingly, false positives increase with $k$ and decrease with $n$, but now we have a model that quantifies the relationship.
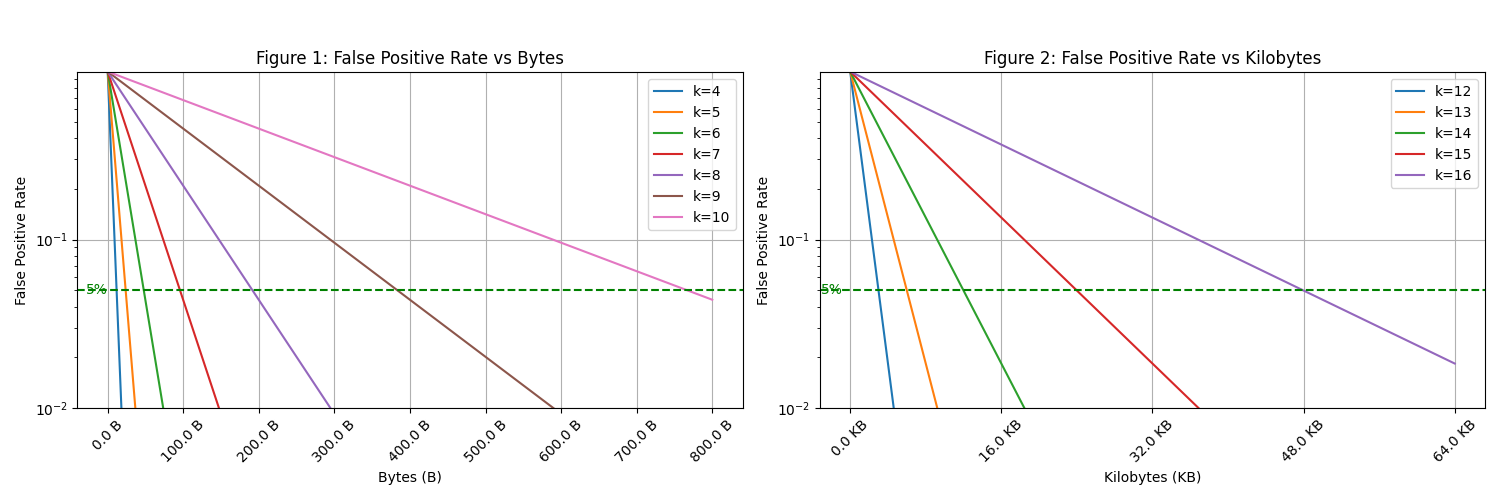
In Figure 1, the false positive rate decreases exponentially as the byte size of the hash increases for smaller sets of elements (k=4 to k=10). In Figure 2, we observe the false positive rate behavior over larger kilobyte sizes for larger sets (k=12 to k=16). The green dashed line represents the 5% false positive rate threshold. As k increases, achieving this threshold requires significantly more space, highlighting the trade-off between set size and hash size.
Subset Relation
The subset relation predicate:
$$ \subseteq_A : 2^{X^{\ast}} \mapsto 2^{X^{\ast}} \mapsto \mathrm{bool} $$defined as
$$ a \subseteq_A b := \forall x \in a, x \in b. $$In approximate Boolean algebra $B$:
$$ \subseteq_B : \lbrace0,1\rbrace^n \times \lbrace0,1\rbrace^n \mapsto \lbrace0,1\rbrace $$defined as
$$ a \subseteq_B b := a | b = a, $$which looks identical to the set-indicator function but has different error probabilities.
Let $W$ and $X$ be bit strings for $F W$ and $F X$. The probability that $W$ is a subset of $X$ requires $W_j = 1 \implies X_j = 1$ for all $j$. Each is logical implication:
$$ W_j = 1 \implies X_j = 1, $$equivalently
$$ \lnot ( W_j = 1 \land X_j = 0 ). $$The probability:
$$ \begin{align*} \Pr\lbrace\lnot ( W_j = 1 \land X_j = 0)\rbrace &= 1 - \Pr\lbrace W_j = 1 \rbrace \Pr\lbrace X_j = 0\rbrace \\ &= 1 - (1 - 2^{-k_1}) 2^{-k_2}, \end{align*} $$where $k_1$ and $k_2$ are the sizes of $W$ and $X$.
For a false positive on $W \subseteq X$, this must hold for all $n$ positions:
$$ \begin{align*} \varepsilon &= \Pr\lbrace\text{$W \subseteq X$ is a false positive}\rbrace\\ &= \bigl(1 - (1 - 2^{-k_1}) 2^{-k_2}\bigr)^n. \end{align*} $$Approximating:
$$ \varepsilon_{\subseteq} \approx e^{-n (1 - 2^{-k_1}) 2^{-k_2}}, $$and applying the approximation again to $1 - 2^{-k_1}$:
$$ \varepsilon_{\subseteq} \approx e^{-n e^{-(k_1 + k_2 \log 2)}}. $$In Big-O with fixed $n$:
$$ \varepsilon_{\subseteq} = e^{\mathcal{O}(e^{-m})}, $$where $m = k_1 + k_2 \log 2$. So $\varepsilon_{\subseteq}$ approaches 1 exponentially fast as $m$ increases. Consistent with the membership relation analysis.
Since equality can be written as $A \subseteq B \land B \subseteq A$, the false positive rate for equality is the product of the false positive rates for both subset directions.
Two-Level Hashing Scheme
The single-level scheme requires exponentially growing bit strings. To address this, I introduce a two-level scheme that reduces space complexity for practical use.
The construction:
- A hash function outputs $q$ bits.
- The first $w$ bits determine which bin the element goes in ($2^w$ bins total).
- The remaining $q-w$ bits represent the element within the bin.
- Total: $n = 2^w(q-w)$ bits.
False Positive Rate
Membership Relation
Assume $k$ elements are in the set and we test membership of $x$. No false negatives, as before. A false positive occurs when:
- With probability $2^{-w}$, $x$ maps to some particular bin.
- That bin, represented by $n-w$ bits, has an expected $k / 2^w$ elements.
- Using the earlier derivation for the per-bin false positive rate:
Fixing $w$ and $q$:
$$ \varepsilon(k) = e^{\mathcal{O}(2^{-k})}, $$asymptotically the same as the single-level scheme, but much more practical for reasonably large sets.
Space complexity: $n = 2^w (q-w)$ bits, or $m = 2^w (q-w) / k$ bits per element, for false positive rate $\varepsilon(k,w,q)$.
In Figure 3, we show the false positive rate for different values of $w$ and $q$.
C++ Implementation: Single-Level Hashing Scheme
Here is a C++ implementation modeling the Boolean algebra over trapdoors. I generalize trapdoors to any type $X$, parameterized over hash size $N$.
Each trapdoor<X,N> represents a value of type X as an $N$-byte hash using a cryptographic hash function. It models equality as a Bernoulli Boolean with a false positive rate of $2^{-8N}$ and a false negative rate of $0$. In Bernoulli Model notation:
where $X’$ is a trapdoor of type $X$ and the latent value is the equality predicate.
The trapdoor_set<X,N> class represents an approximate Boolean algebra over trapdoors. It extends trapdoor<X,N> with these operations:
empty_trapdoor_set<X,N>()returns the empty set ($0_B$).universal_trapdoor_set<X,N>()returns the universal set ($1_B$).operator+(trapdoor_set<X,N> const & x, trapdoor_set<X,N> const & y)returns the union ($\lor_B$).operator~(trapdoor_set<X,N> const & x)returns the complement ($\neg_B$).operator*(trapdoor_set<X,N> const & x, trapdoor_set<X,N> const & y)returns the intersection ($\land_B$).empty(trapdoor_set<X,N> const & xs)returns a Bernoulli Boolean for emptiness, with false positive rate $\varepsilon = 2^{-8N}$.in(trapdoor<X,N> const & x, trapdoor_set<X,N> const & xs)returns a Bernoulli Boolean for membership. See the Relational Predicates section for details.
For closure, the class has a hash member function returning the stored hash, enabling composition of operations (e.g., creating a powerset of trapdoor_set objects).
#include <array>
template <typename X, size_t N>
struct trapdoor
{
using value_type = X;
/**
* The constructor initializes the value hash to the given value hash.
* Since the hash is a cryptographic hash, the hash is one-way and so we
* cannot recover the original value from the hash.
*
* This also models the concept of an Oblivious Type, where the true value
* is latent and we permit some subset of operations on it. In this case,
* the only operation we permit is the equality and hashing operations.
*
* @param value_hash The value hash.
*/
trapdoor(std::array<char, N> value_hash) : value_hash(value_hash) {}
/**
* The default constructor initializes the value hash to zero. This value
* often denotes a special value of type X, but not necessarily.
*/
trapdoor() { value_hash.fill(0); }
std::array<char, N> value_hash;
};
/**
* The hash function for the trapdoor class. It returns the value hash.
*/
template <typename X, size_t N>
auto hash(trapdoor const & x)
{
return x.value_hash;
}
/**
* Basic equality operator. It returns a Bernoulli Boolean that represents
* a Boolean value indicating if the trapdoors are equal with a false positive rate
* of 2^{-8 N}. Different specializes of the trapdoor class may have different
* false positive rates, but this is a reasonable default value.
*/
template <typename X, size_t N>
auto operator==(trapdoor const & lhs, trapdoor const & rhs) const
{
return bernoulli<bool>{lhs.value_hash == rhs.value_hash, -8*N};
}
/**
* The `or` operation in the Boolean algebra over bit strings.
*/
template <typename X, size_t N>
auto lor(trapdoor lhs, trapdoor const & rhs)
{
for (size_t i = 0; i < N; ++i)
lhs.value_hash[i] |= rhs.value_hash[i];
return lhs;
}
/**
* The `and` operation in the Boolean algebra over bit strings.
*/
template <typename X, size_t N>
auto land(trapdoor lhs, trapdoor const & rhs)
{
for (size_t i = 0; i < N; ++i)
lhs.value_hash[i] &= rhs.value_hash[i];
return lhs;
}
/**
* The `not` operation in the Boolean algebra over bit strings.
*/
template <typename X, size_t N>
auto lnot(trapdoor x)
{
for (size_t i = 0; i < N; ++i)
lhs.value_hash[i] = ~lhs.value_hash[i];
return lhs;
}
template <typename T>
auto minimum() { return std::numeric_limits<T>::min(); }
template <typename T>
auto maximum() { return std::numeric_limits<T>::max(); }
/**
* The `minimum` operation in the Boolean algebra over trapdoors
*/
template <typename trapdoor<typename X, size_t N>>
auto minimum() { return trapdoor<X,N>(); }
/**
* The `maximum` operation in the Boolean algebra over trapdoors
*/
template <typename trapdoor<typename X, size_t N>>
auto maximum()
{
trapdoor<X,N> x;
x.value_hash.fill(std::numeric_limits<char>::min())
return x;
}
/**
* The trapdoor_set class models an approximate Boolean algebra over trapdoors.
* It is a specialization of the trapdoor class that implements additional operations
* that can take place over the domain of trapdoor and trapdoor_set.
*/
template <typename X, size_t N>
struct trapdoor_set: public trapdoor<X,N>
{
trapdoor_set(
double low_k = 0,
double high_k = std::numeric_limits<double>::infinity()),
std::array<char, N> value_hash)
: trapdoor<trapdoor_set<X,N>,N>(value_hash),
low_k(low_k),
high_k(high_k) {}
trapdoor_set() : trapdoor<trapdoor_set<X,N>,N>(), low_k(0), high_k(0) {}
trapdoor_set(trapdoor_set const &) = default;
trapdoor_set & operator=(trapdoor_set const &) = default;
double low_k;
double high_k;
};
/**
* The size (cardinality) of the latent set (the set the trapdoor_set represents).
*
* @param xs The trapdoor_set.
* @return The size range of the set.
*/
template <typename X, size_t N>
auto size(trapdoor_set<X,N> const & xs)
{
return std::make_pair(xs.low_k, xs.high_k);
}
/**
The union operation.
*/
template <typename X, size_t N>
auto operator+(
trapdoor_set<X,N> const & xs,
trapdoor_set<X,N> const & ys)
{
return trapdoor_set<X,N>(lor(xs, ys).value_hash,
std::max(xs.low_k, ys.low_k), xs.high_k + ys.high_k);
}
template <typename X, size_t N>
void insert(trapdoor<X,N> const & x, trapdoor_set<X,N> & xs)
{
for (size_t i = 0; i < N; ++i)
xs.value_hash[i] |= x.value_hash[i];
// since x could already be in xs, we do not increment the low_k
// only the high_k
xs.high_k += 1;
}
template <typename X, size_t N>
auto operator~(trapdoor_set<X,N> x)
{
for (size_t i = 0; i < N; ++i)
x.value_hash[i] = ~x.value_hash[i];
// assume |x| in [a, b]
// then |~x| has the following analysis.
// - if |x| = a, then |~x| = |U| - a, where |U| is universal set
// - if |x| = b, then |~x| = |U| - b
// so, |~x| in [|U|-b, |U|-a]
x.low_k = maximum<X>() - x.high_k;
x.high_k = maximum<X>() - x.low_k;
return x;
}
template <typename X, size_t N>
auto operator*(
trapdoor_set<X,N> const & x,
trapdoor_set<X,N> const & y)
{
return trapdoor_set<X>(x.value_hash & y.value_hash,
0, // intersection could be empty
std::min(x.high_k, y.high_k) // one could be a subset of the other
);
}
template <typename X, size_t N>
bernoulli<bool> in(trapdoor<X,N> const & x, trapdoor_set<X,N> const & xs
{
for (size_t i = 0; i < N; ++i)
if ((x.value_hash[i] & xs.value_hash[i]) != x.value_hash[i])
return bernoulli<bool>{true, 0};
// earlier, we showed that the fp rate is (1 - 2^{-k})^n
return bernoulli<bool>{false, };
}
/**
* The subseteq_B predicate, x \subseteq_B y, is defined as x | y = x.
* It has an false positive rate of eps = (1 - 2^{-(k_1 + k_2 log 2)})^n
* which we approxiate as eps ~ e^{-n e^{-(k_1 + k_2 log 2)}}.
* we store the log(eps) instead: -n e^{-(k_1 + k_2 log 2)}
*/
template <typename X>
bernoulli<bool> operator<=(
trapdoor_set<X> const & x,
trapdoor_set<X> const & y)
{
for (size_t i = 0; i < N; ++i)
if ((x.value_hash[i] & y.value_hash[i]) != x.value_hash[i])
{
return bernoulli<bool>(false, 0); // false negative rate is 0
}
// earlier, we showed that the fp rate is (1 - 2^{-(k_1 + k_2 log 2)})^n
return bernoulli<bool>{true, };
}
template <typename X>
bernoulli<bool> operator==(
trapdoor_set<X> const & x
trapdoor_set<X> const & y)
{
for (size_t i = 0; i < N; ++i)
if (x.value_hash[i] != y.value_hash[i])
return bernoulli<bool>{false, 0.5};
}
Appendix
Marginal Uniformity
Suppose we have a probability distribution over elements (unigrams) in $X^{\ast}$ such that
$$ \Pr_D\lbrace a\rbrace $$is the probability of $a$ being generated from some data generating process $D$. We can transform homomorphism $F$ to map each $a \in X$ to multiple hashes inversely proportional to $\Pr_D(a)$, satisfying
$$ \Pr\lbrace h(a)\rbrace \approx \Pr\lbrace h(b)\rbrace $$even if $\Pr_D\lbrace a\rbrace$ and $\Pr_D\lbrace b\rbrace$ are significantly different.
When doing a membership query, we uniformly sample one of these representations so that the unigram distribution of elements in $\lbrace0,1\rbrace$ is uniform. This is a kind of marginal uniformity.
However, this approach has serious shortcomings:
Only the marginal distribution of unigrams is uniformly distributed. Correlations in the joint distributions of $X^{\ast}$, such as bigrams, are not accounted for. We can apply the transformation to larger sequences, but space complexity grows exponentially with sequence length for a fixed false positive rate. In practice, even the unigram model may need approximation due to space limits.
When we apply Boolean operations on an untrusted system, it cannot be given distribution information about elements in $X$. This means Boolean operations like $\land$ and $\lor$ cannot be performed on the untrusted system, only relational queries like $\in$ and $\subseteq$.
Discussion